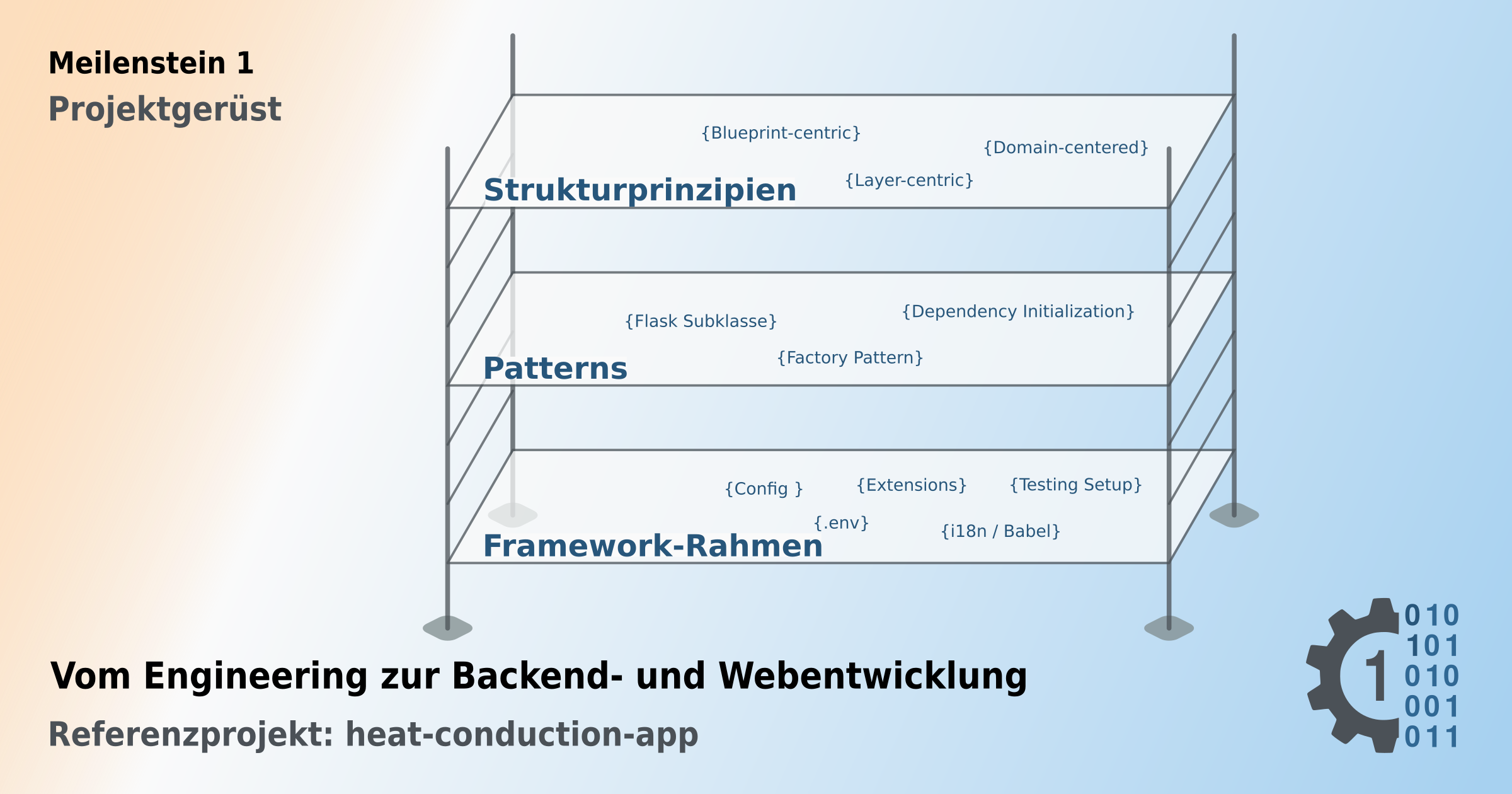
Applikationsstruktur - Vom Konzept zur konkreten Implementierung
heat-conduction-app: Referenzprojekt für moderne Backend- und Webarchitektur
Softwarearchitektur Applikationsstruktur Projektgerüst Backend Flask heat-conduction-app
← Zurück zur Übersicht | ← Einführungspost - Teil 3 | Meilenstein 2 - Erste Berechnung läuft →
Einleitung
Die Einführungsreihe (← Teil 1, ← Teil2, ← Teil 3) hatte das Ziel, einen übergeordneten Blick auf die Verbindung von Ingenieurwissen und moderner Softwareentwicklung zu werfen.
Ausgehend von einem realen, aber stark reduzierten physikalischen Problem habe ich darin verschiedene konzeptionelle Ebenen und Denkmodelle vorgestellt, vom Problemraum über Architekturentscheidungen bis hin zum Software-Stack. Die Einführungsreihe beschäftigte sich dabei noch nicht mit der konkreten Implementierung im Code, sondern mit einer abstrahierten Betrachtung des Gesamtzusammenhangs.
Diese Fokussierung ist bewusst. Aus meiner langjährigen Erfahrung in der Industrie habe ich mitgenommen, dass genau diesem konzeptionellen Überbau häufig zu wenig Aufmerksamkeit geschenkt wird. Er wird nicht selten als "Zeitverschwendung" wahrgenommen, insbesondere, weil in dieser Phase noch wenig sichtbarer Code entsteht.
Ich halte dies für einen Fehler. Gerade dann, wenn zwei Domänen aufeinandertreffen, hier die Ingenieurwissenschaft und Softwareentwicklung, ist ein gemeinsames Strukturverständnis entscheidend. Ich denke dies gilt für nahezu jedes Softwareprojekt, da das eigentliche Problem fast immer aus einer Nicht-Informatik-Domäne stammt. Umso wichtiger ist es, früh die richtigen Abstraktionen, Werkzeuge und Strukturen zu wählen.
Projektkontext
Dieser Artikel ist Teil zur Serie zur heat-conduction-app. Der aktuelle Stand ist im Repository verfügbar, die Anwendung läuft produktiv unter einer eigenen Subdomain.
- Phase 1 abgeschlossen
- Deployment (M5)
- Datenbankintegration (M4)
- Erste UI-Demo (M3)
- Erste Berechnung läuft (M2)
- Projektgerüst (dieser Artikel)
Einführung und Hintergrund?
Einleitung
lesen
Die Implementierungsebene einer technischen Web-Applikation
Mit diesem Meilenstein verlasse ich diese konzeptionelle Ebene und wende ich mich nun der konkreten Umsetzung der Applikation zu. Im Fokus steht die Implementierungsebene einer technischen Berechnungs-Applikation als Webanwendung mit dem Flask-Framework.
An diesem Punkt wird sichtbar, dass die grundlegenden Strukturentscheidungen bereits getroffen sind. Das Problem ist verstanden, das Entwicklungsmodell definiert und der Software-Stack gewählt. Nun geht es darum, wie diese Entscheidungen innerhalb eines konkreten Frameworks in Code übersetzt werden.
Im Zentrum stehen dabei zwei zentrale Fragen:
- Wie ist die Anwendung innerhalb des Frameworks strukturiert?
- Wie ist der Code organisiert, damit er wartbar, testbar und erweiterbar bleibt?
Entscheidungen wie das 4-Phasen-Entwicklungsmodell oder der gewählte Technologie-Stack bilden hier die Grundlage. Wer sich für die konzeptionellen Hintergründe interessiert, findet diese ausführlich in Teil 3 der Einführungsreihe.
Die folgende Grafik ordnet den aktuellen Fokus ein und markiert den Übergang von Konzept und Architektur zur konkreten Umsetzung.
Applikationsstruktur: Wie ist die Anwendung innerhalb des Frameworks organisiert?
Eine der wichtigsten Entscheidungen bei der Umsetzung einer Webanwendung ist die Wahl der Applikations- und Modulstruktur. Sie bestimmt nicht nur, wie der Code organisiert ist, sondern prägt auch maßgeblich die Denk- und Arbeitsweise im Projekt. Soll die Struktur primär Verantwortlichkeiten trennen, steht die fachliche Gliederung im Vordergrund oder soll die eigentliche Domäne möglichst vollständig vom Framework entkoppelt werden? Diese Entscheidung sollte sorgfältig getroffen werden, denn insbesondere bei mittleren und größeren Anwendungen lässt sich die grundlegende Struktur später nur mit erheblichem Aufwand verändern. Die folgenden Ansätze stellen keine vollständige oder abschließende Liste dar, zeigen jedoch typische Denkmuster, die in der Praxis häufig anzutreffen sind, teilweise auch in Kombination.
Layered-Approach
Im Rahmen meiner bisherigen Java/SpringBoot-Projekte basierte die Applikationsstruktur des Backends überwiegend auf einem klassischen Schichten-Ansatz:
Controller
↓
Service ← Model
↓
RepositoryDie Controller-Schicht bildet dabei den HTTP- bzw. Applikations-Layer und ist häufig als eine REST-API ausgeprägt. Darunter liegt die Service-Schicht, die die gesamte Geschäfts- und Fachlogik kapselt. Gerade bei technischen Berechnungswerkzeugen kann diese Schicht sehr umfangreich werden, da hier die eigentlichen physikalischen Modelle und Berechnungsabläufe implementiert sind.
Die Model-Schicht beschreibt die fachlichen Datenstrukturen, beispielsweise zur Abbildung von physikalischen Größen, Materialparametern oder Systemzuständen. Die Repository-Schicht übernimmt schließlich die die Aufgabe, diese Daten aus einer Datenbank zu lesen oder dort zu persistieren.
Der Schichtenansatz ermöglicht eine klare Trennung der Verantwortlichkeiten und eignet sich besonders gut für Anwendungen mit umfangreicher Business- und Fachlogik. Er ist in der Java-Welt weit verbreitet und dort gut etabliert.
Domain-Centered-Approach
Ein weiterer, bei komplexeren Anwendungen häufig anzutreffender Ansatz ist eine stärker Domänen-zentrierte Architektur. Ziel ist es, fachliche Domänen als eigenständige Einheiten zu modellieren und möglichst unabhängig voneinander umzusetzen. Die Trennung erfolgt dabei nicht primär nach technischen Verantwortlichkeiten, sondern nach Fachlichkeit.
Je nach Anwendung kann diese Trennung auf unterschiedlichen Ebenen erfolgen. So könnten beispielweise einzelne Wärmetransportmechanismen wie Konduktion, Konvektion und Strahlung jeweils eigene Domänen bilden, oder es wird eine fachlich höhere Ebene gewählt, etwa "Wärmetransport" und "Strömungsmechanik" als getrennte Wissensbereiche.
Modelle und Services bilden den Kern einer solchen Domäne, da sie eng mit dem fachlichen Problemraum verknüpft sind. Idealerweise sind diese Domänen vollständig vom Web-Framework, vom Routing und von der konkreten Datenbanktechnologie entkoppelt. Die Domäne definiert lediglich Schnittstellen (z.B. Repository-Interfaces), die von einer separaten Infrastruktur-Schicht implementiert werden.
Ansätze dieser Art finden sich unter anderem in Architekturstilen wie Domain-Driven- Design, Clean Architecture oder Hexagonal Architecture wieder. Selbst habe ich diesen Stil bislang noch nicht in einer Anwendung vollständig umgesetzt. Für umfangreiche, fachlich komplexe Berechnungslogiken ist er jedoch ein sehr interessanter Kandidat und bildet einen wichtigen Referenzpunkt bei der Architekturentscheidung.
Application Package Architecture ("App as a Package")
Ein deutlich minimalistischerer Ansatz ist die sogenannte Application-Package-Architektur auch bekannt als "Flat App Structure". Dabei existiert im Wesentlichen nur ein zentrales App- oder Main-Package, das alle Module enthält. Es erfolgt weder eine klare Trennung nach Fachlichkeit noch nach Verantwortlichkeiten.
Dieser Ansatz lässt sich mit Python und Flask sehr einfach umsetzen und erfordert zunächst nur wenig Boilerplate. Für kleine Projekte oder Prototypen kann dies durchaus attraktiv sein. In Bezug auf Erweiterbarkeit, Skalierbarkeit und Wartbarkeit stößt diese Struktur jedoch schnell an ihre Grenzen.
Gerade bei Berechnungssoftware zeigt die Erfahrung, dass der Funktionsumfang häufig wächst, sobald der Mehrwert einer zentral gepflegten Anwendung erkannt wird. Für solche Szenarien ist dieser Ansatz aus meiner Sicht nur eingeschränkt geeignet.
Blueprint-Approach (Flask)
Als framework-spezifischen Ansatz bietet Flask mit den sogenannten Blueprints ein zentrales Strukturierungswerkzeug. Die Flask-Dokumentation beschreibt Blueprints wie folgt:
Flask uses a concept of blueprints for making application components and supporting common patterns within an application or across applications. A Blueprint object works similarly to a Flask application object, but it is not actually an application.
Ein Blueprint ist eine gekapselte Komponente, die sich ein Stück weit wie eine "Anwendung in der Anwendung" verhält. Er kann Routen, Templates, statische Dateien und weitere Bestandteile bündeln und wird explizit in der Hauptanwendung registriert. Im Idealfall lässt sich ein Blueprint relativ einfach von einer Anwendung in eine andere übertragen.
Blueprints eignen sich sehr gut, um zentrale Aufgaben einer
Webanwendung voneinander zu trennen, etwa ein
auth-Blueprint für Authentifizierung, ein
api-Blueprint für eine REST-Schnittstelle und ein
main-Blueprint für die fachliche Domäne. Bei
serverseitigem Rendering (SSR) können Blueprints zudem Templates
enthalten und damit nahezu eigenständige Fullstack-Einheiten
bilden.
Wichtig ist dabei die Abgrenzung zu Flask-Extensions. Extensions sind keine Blueprints, sondern infrastrukturelle Erweiterungen, die zusätzliche Funktionalität bereitstellen und sich an den Lebenszyklus der Applikation anbinden.
Fazit: Die gewählte Struktur der heat-conduction-app
Im Rahmen des Signature-Projekts
heat-conduction-app habe ich mich für eine pragmatische
Kombination aus einem Blueprint-zentrierten Ansatz und einer
klassischen Schichtenarchitektur entschieden. Blueprints bilden
die modulare Grundstruktur der Anwendung und gehören zu den
Kernfeatures von Flask. Innerhalb des fachlich dominanten
main-Blueprints wird zusätzlich ein klares
Schichtenmodell umgesetzt:
routesals HTTP- bzw. Application-Layerserviceals Domain- und Service-Layerrepositoryals Data-Layer
Die Infrastruktur in Form der Datenbankmodelle ist übergeordnet
im Modul models.py angesiedelt. Sie enthält die
SQL-Alchemy-ORM-Klassen und wird von allen Blueprints gemeinsam
genutzt. Die Datenbank ist damit global für die Anwendungen
verfügbar.
Es handelt sich dabei nicht um eine strikte domain-zentrierte Architektur im Sinne von Domain-Driven Design, sondern um eine gewählte flask-idiomatische Struktur, die sich gut für MVPs und wachsend komplexe Anwendungen eignet. Und gleichzeitig eine saubere Brücke zu stärker domänenzentrierten Architekturen in späteren Phasen offen lässt Die folgende Grafik fasst diese Struktur und die getroffenen Entscheidungen auf Applikationsebene zusammen.
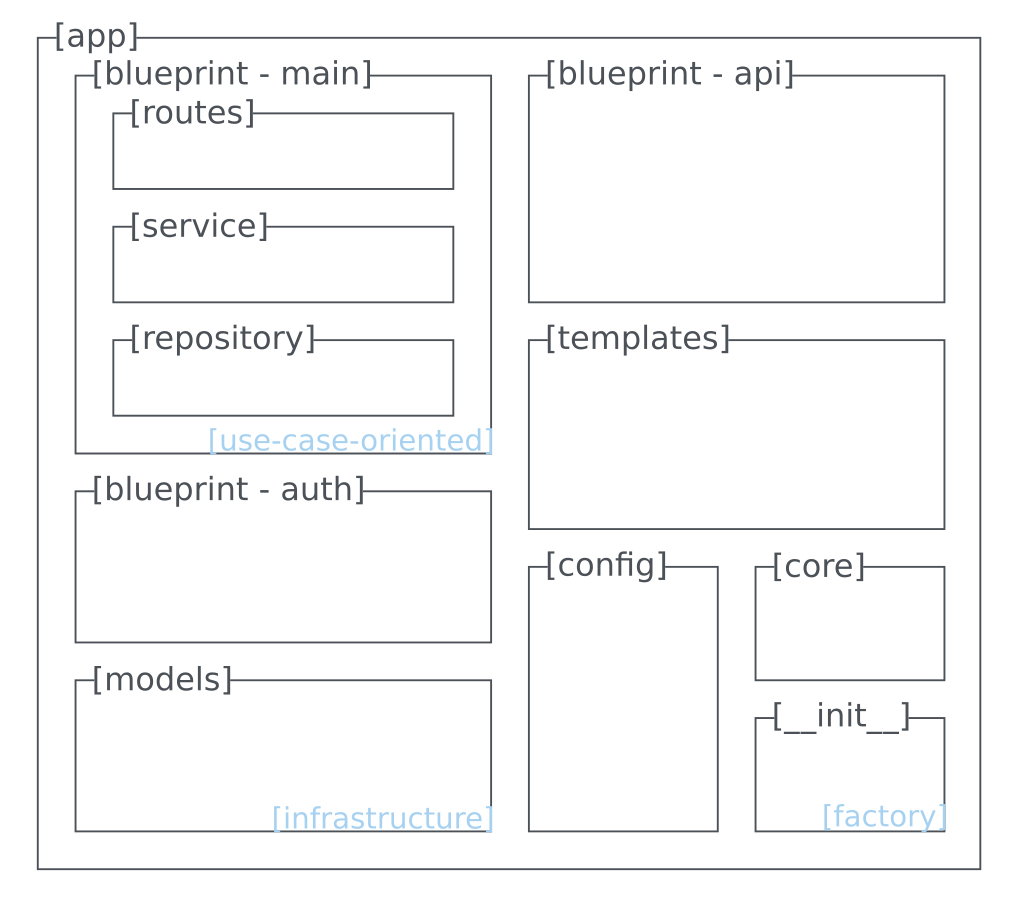
Applikationserstellung und technisches Grundgerüst
Nachdem die grundsätzliche Applikationsstruktur festgelegt ist, stellt sich die Frage, wie diese Struktur technisch umgesetzt und gesteuert wird. In diesem Abschnitt geht es weniger um Fachlogik oder Features, sondern um die technisches Mechanismen, die das Verhalten der Anwendung definieren:
- Wie wird die App erzeugt?
- Wie werden Erweiterungen eingebunden?
- Wie bleibt die Anwendung testbar und erweiterbar?
Config und Env-Handling
Config und Env-Handling dienen dazu, die Applikation auf unterschiedliche Laufzeitkontexte vorzubereiten, etwa Development, Testing oder Produktivbetrieb. Dabei geht es nicht nur um die Datenbankanbindung, sondern auch um sicherheitsrelevante Parameter wie Secret Keys für CSRF-Schutz, Session-Handling und externe Services.
In der heat-conduction-app werden Umgebungsvariablen
über .env sowie Flask-spezifische Variablen über
.flaskenv bereitgestellt. Diese werden beim Start
der Anwendung geladen und durch eine zentrale Config-Klasse
verarbeitet. Die Config-Klasse selbst ist in mehrere Profile
unterteilt (z.B. Development, Test, Production), die jeweils
sinnvolle Default-Werte setzen.
Gerade für automatisierte Tests ist dieser Ansatz entscheidend, Test-spezifische Konfigurationen wie temporäre Datenbanken oder deaktivierte Sicherheitsmechanismen lassen sich gezielt aktivieren, ohne den Anwendungscode zu verändern.
Darüber hinaus können Umgebungsvariablen auch Metainformationen enthalten, etwa Versionsnummern, Build-Informationen oder Kontaktdaten, die für Betrieb und Wartung relevant sind.
Factory Pattern: reproduzierbare App-Erstellung
Die Flask-Applikation wird nicht direkt instanziiert, sondern über eine Factory-Methode erzeugt. Dieses Factory Pattern ist ein zentrales Steuerungselement der Anwendung.
Die Factory übernimmt unter anderem folgende Aufgaben:
- Erzeugen der Flask-App-Instanz
- Laden und Anwenden der Konfiguration
- Initialisierung der Flask-Extensions
- Registrierung der Blueprints
- Einrichten von CLI-Kommandos
- Registrierung von Shell-Context-Prozessoren
Ein entscheidender Vorteil, die Anwendung ist reproduzierbar und kann mit unterschiedlichen Konfigurationen mehrfach instanziiert werden, etwa für Tests, lokale Entwicklung oder produktiven Betrieb.
Flask-Subklasse als technischer Integrationspunkt
Um die Factory schlank zu halten und technische Querschnittthemen zu bündeln, wird in diesem Projekt eine eigene Flask-Subklasse verwendet. Diese Subklasse kapselt die Initialisierung und Verwaltung der Extensions sowie weitere applikationsweite Attribute.
Dadurch entsteht ein klarer technischer Integrationspunkt:
- Extensions werden zentral definiert und typisiert
- globaler Applikationszustand wird explizit modelliert
- der Shell-Kontext kann sauber gebündelt werden
- das schleichende Anwachsen globaler Variablen wird vermieden
Wichtig ist dabei, den Konstruktor der Subklasse schlank zu halten und zyklische Importe zu vermeiden. Business-Logik gehört nicht in diese Ebene.
Ein vereinfachter Überblick über die zentralen Steuerungsmodule sieht wie folgt aus:
app/
__init__.py → Factory Methode
__main__.py → Startpunkt der App
core.py → Flask-Subklasse, Extensions
config.py → Config-Profile
cli.py → CLI-Kommandos
models.py → Infrastruktur (ORM)Extension-Setup und Infrastruktur
Ein wesentlicher Grund für die Wahl von Flask ist die Möglichkeit, die Anwendung schrittweise über Extensions zu erweitern. Bereits in Phase 1 wird folgende Basisausstattung eingebunden:
- Flask-WTF für Formulare und CSRF-Schutz
- flask-babel für Internationalisierung
- flask-sqlalchemy als ORM
- flask-migrate für Datenbankmigrationen
Flask-SQLAlchemy und Flask-Migrate bilden gemeinsam die Persistenz-Infrastruktur und greifen auf die global definierten Modelle zu. Flask-WTF unterstützt den serverseitigen Rendering-Ansatz mit Jinja-templates. Flask-Babel wird früh integriert, da Internationalisierung später nur mit deutlich höherem Aufwand nachrüstbar ist.
Shell Context
Über einen Shell-Context-Prozessor werden häufig genutzte Objekte (z.B. App, Datenbank, Modelle) automatisch in die Flask-Shell eingebunden. Dies hilft bei der täglichen Arbeit, erleichtert das Debugging, Exploration und Ad-hoc-Tests erheblich und fördert einen interaktiven Umgang mit der Anwendung, bei fachlich geprägten Projekten ein Vorteil.
Testbarkeit
Die beschriebenen technischen Steuerungsmechanismen sind kein Selbstzweck. Sie bilden die Grundlage für eine gut testbare Anwendung. Durch die Factory-Methode lassen sich isolierte Test-Applikationen erzeugen, die mit einer eigenen Konfiguration und einem eigenen Test-Client betrieben werden.
Test sind von Beginn an teil des Projekts und werden mit
pytest umgesetzt. Eine dezidierte Testkonfiguration
stellt sicher, dass Tests reproduzierbar, schnell und unabhängig
vom Produktivsystem ausgeführt werden können.
Erstellung eines reproduzierbaren Projektgerüst
Applikationsstruktur und technisches Grundgerüst sind definiert, nun folgt die konkrete Erstellung des Projektgerüst und damit die Frage:
Wie wird aus diesen konzeptionellen Entscheidungen ein konsistentes, reproduzierbares Projektgerüst?
Ein häufiger Weg besteht darin, ein vergleichbares Projekt zu kopieren, anschließend alles bis auf die Grundstruktur zu entfernen und fehlende Dateien schrittweise zu ergänzen. Alternativ wird mit einem leeren Projekt begonnen, Ordner werden manuell angelegt, Konfigurationsdateien aus anderen Projekten übernommen und Abhängigkeiten sukzessive ergänzt. Diese Vorgehensweisen sind pragmatisch und weit verbreitet, führen jedoch oft zu inkonsistenten Strukturen und schwer reproduzierbaren Setups.
Da mein Ziel mit der heat-conduction-app nicht nur die Umsetzung eines konkreten Problems, sondern auch die Etablierung einer belastbaren und wiederholbaren Arbeitsweise ist, habe ich mich gegen ein manuelles Setup entschieden.
Stattdessen wird die zuvor entwickelte Applikationsstruktur in ein Template überführt, aus dem das Projektgerüst automatisch erzeugt wird.
Reproduzierbarkeit: Applikationsstruktur als Template mit init-pyproj
An dieser Stelle kommt ein Werkzeug zum Einsatz, das ich bereits in einem separaten Blogpost vorgestellt habe: die init-pyproj-app.
Bei init-pyproj handelt es sich um ein Shell-basiertes Tool, das es ermöglicht, Projektvorlagen (Templates) zu definieren und daraus neue Python-Projekte zu initialisieren. Ein solches Template beschreibt dabei nicht nur die Ordner- und Modulstruktur, sondern kann auch:
- eine virtuelle Umgebung anlegen
- Abhängigkeiten installieren
- ein lokales Git-Repository initialisieren
- Konfigurations- und Meta-Daten bereitstellen
Für die im vorherigen Abschnitt beschriebene
Applikationsstruktur habe ich ein eigenes Template mit dem Namen
flask-blueprint angelegt. Dieses template bildet
die Kombination aus Blueprint- zentrierter Struktur, klassischem
Schichten-Ansatz innerhalb der fachlichen Module sowie dem
technischen Grundgerüst (Factory-Pattern, Extensions,
Config-Handling) explizit ab.
Damit wird die Architekturentscheidung nicht nur dokumentiert, sondern operationalisiert: Das Projektgerüst entsteht reproduzierbar, konsistent und in wenigen Sekunden, unabhängig davon, ob es sich um ein Einzelprojekt oder den Startpunkt weiterer Anwendungen handelt.
Ergebnis: Das initiale Projektgerüst der heat-conduction-app
Das folgende Verzeichnislayout ist
kein manuell erstelltes Beispiel, sondern das
konkrete Ergebnis des flask-blueprint-Templates der
init-pyproj-app:
app/
__init__.py → Factory Methode
__main__.py → minimaler Startpunkt
cli.py → Click-basierte CLI Funktionen
config.py → Config und Env-Handling
core.py → Flask-Subklasse & Extension-Setup
models.py → Infrastruktur / ORM-Modelle
templates/
base.html
index.html
static/
style.css
main/ → fachlicher Blueprint
__init__.py → Blueprint-Initialisierung
forms.py
repository.py → Data Layer
routes.py → HTTP / Applikation Layer
service.py → Domain / Service Layer
auth/ → Auth-Blueprint (Platzhalter)
api/ → API-Blueprint (Platzhalter)
tests/
conftest.py → Test-App & Test-Client
main/
test_route.py
.env → allgemeine Umgebungsvariablen
.flaskenv → Flask spezifische Variablen
babel.cfg → Übersetzungsquellen
LICENSE
pyproject.toml → Projektkonfiguration & Abhängigkeiten
README.mdDieses Gerüst bildet den technischen Startpunkt der Umsetzung. Es enthält noch keine Fachlogik, sondern stellt die strukturellen und infrastrukturellen Voraussetzungen bereit, um die folgenden Entwicklungsphasen sauber und kontrolliert umzusetzen.
Fazit und Ausblick
Mit der Implementierungsebene und der damit verbundenen Applikationsstruktur beginnt die konkrete Umsetzung der heat-conduction-app. Die Nutzung des init-pyproj-Tools zwingt an dieser Stelle zu klaren Entscheidungen und fördert den Gedanken der Wiederverwendbarkeit bereits sehr früh im Projektverlauf. Architektur wird dadurch nicht nur entworfen, sondern direkt in ein reproduzierbares Projektsetup überführt.
Das initialisierte lokale Git-Repository wird im letzten Schritt mit einem Remote-Repository verbunden. Das Projektgerüst der heat-conduction-app steht und ist öffentlich im ← Codeberg-Repository einsehbar.
Auch wenn die Implementierung in diesem Projekt aktuell auf Python und Flask basiert, ist die zugrunde liegende Struktur so gewählt, dass sie nicht an ein spezifisches Framework gebunden ist. Die Kombination aus klarer Applikationsstruktur, Factory-basierter Initialisierung, Layering, modularem Aufbau und expliziter Infrastruktur ist ebenso auf Java/Spring Boot übertragbar.
Das Projekt versteht sich nicht als Flask-Spezialfall, sondern als Referenz für saubere Backend- und Webarchitektur in technischen Anwendungen, unabhängig vom konkreten Technologie-Stack.
Im nächsten Schritt rückt der fachliche Kern der Anwendung in den Fokus "Erste Berechnung läuft - die Formel als Service-Modul". Ziel ist eine erste lauffähige Berechnung, zunächst noch ohne Benutzeroberfläche, ausschließlich testgetrieben, als Grundlage für die weitere fachliche und technische Ausarbeitung und als erster Beweis, dass die Architektur auch auf Code-Ebene trägt.
Feedback, Fragen oder Anregungen sind jederzeit willkommen, gerne per Email oder auch auf LinkedIn.