Teil 3 / 3
Moderne Architektur für technische Web-Applikationen
heat-conduction-app: Referenzprojekt für moderne Backend- und Webarchitektur
Softwarearchitektur 4-Phasen-Modell Backend-Architektur Webanwendung heat-conduction-app
← Zurück zur Übersicht | ← Einführung - Von der Formel zur Software | Meilenstein 1 - Projektgerüst →
Einleitung
Im ersten Teil dieser Einführungsreihe stand mein fachlicher Hintergrund und der Übergang von klassischen Ingenieurtools hin zu moderner Backend- und Webentwicklung im Fokus. Die heat-conduction-app dient dabei als Referenz- und Portfolioprojekt, um typische Anforderungen technischer Berechnungsanwendungen praxisnah abzubilden.
Im zweiten Teil ging es um den fachlich-technischen Kern, vom Fourierschen Gesetz bis zur Frage, wie sich eine physikalische Aufgabenstellung systematisch in strukturierte Softwarelogik übersetzen lässt. Dafür habe ich das Modell der funktionalen Bausteine eingeführt. Es beschreibt auf fachlicher Ebene, was eine Anwendung leisten muss, Domänenmodell, Berechnungslogik, Ein- und Ausgabe sowie deren Orchestrierung, unabhängig vom konkreten Technologie-Stack.
Kontext
Dieser Artikel ist Teil zur Einführungsreihe zur heat-conduction-app. Der aktuelle Stand ist im Repository verfügbar, die Anwendung läuft produktiv unter einer eigenen Subdomain.
- Hintergrund und Neuorientierung
- Von der Formel zur Software
- Architektur und Software-Stack (dieser Artikel)
Konkrete Implementierung?
Weiter zu Start
der Umsetzung
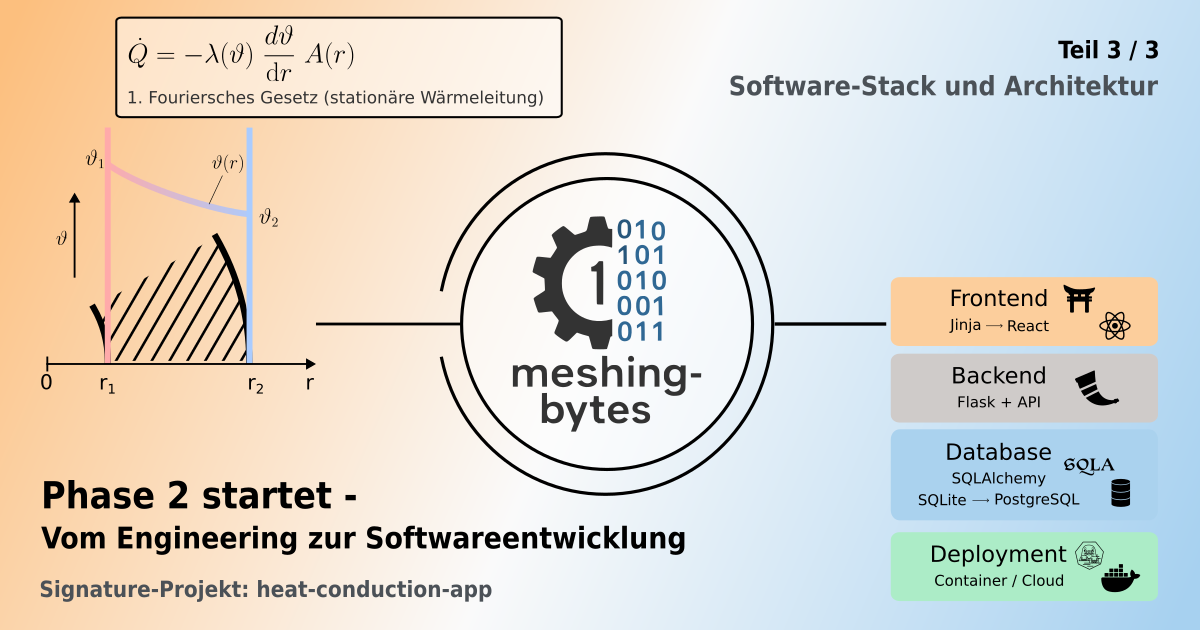
In diesem dritten Teil liegt der Fokus auf der Softwarearchitektur und dem daraus abgeleiteten Technologie-Stack. Ziel ist es zu zeigen, wie sich diese fachlichen Bausteine in eine moderne, wartbare und erweiterbare Web-Architektur überführen lassen. Dabei steht nicht ein einzelnes Framework im Mittelpunkt, sondern ein Architekturansatz, der sich sowohl mit Python (z.B. Flask) als auch mit Java (z.B. Spring Boot) umsetzen lässt. Der gewählte Stack ist daher nicht als "Entweder-oder" zwischen Technologien zu verstehen, sondern als konkretes Referenzbeispiel für einen leichtgewichtigen, modularen Startpunkt.
Als methodische Grundlage dient ein schrittweises Entwicklungsmodell, das die Anwendung in klar definierten Phasen wachsen lässt, von einem schnellen Prototyp über eine stabile Persistenzschicht bis hin zu API-zentrierten Architekturen und optional entkoppelten Frontends. Dieses Vorgehen hilft, technische Komplexität kontrolliert zu erhöhen und Architekturentscheidungen an den tatsächlichen Anforderungen auszurichten.
Softwarearchitektur - eine grundlegende Entscheidung
Bevor ich auf konkrete Technologien eingehe, lohnt sich ein Blick auf Systemebene: Um was für eine Art von Software handelt es sich hier eigentlich?
Ausgehend von den funktionalen Bausteinen aus Teil 2 ergeben sich klare fachliche Anforderungen: ein Domänenmodell für Materialien und Parameter, eine zentrale Berechnungslogik, strukturierte Eingaben, nachvollziehbare Ausgaben sowie eine übergeordnete Orchestrierung, die diese Elemente verbindet.
Diese fachlichen Bausteine lassen sich unabhängig von der Programmiersprache in eine klassische Web-Architektur überführen, mit klarer Trennung von Backend, Frontend und Datenhaltung. Ob die fachliche Logik dabei in Java oder Python implementiert wird, ist zunächst eine technologische Entscheidung, die grundlegende Architektur bleibt gleich.
Der fachliche Kern, also Rechenkern, Validierung und Orchestrierung, liegt dabei im Backend. Das Frontend übernimmt die Eingabe und Darstellung der Ergebnisse, während die Datenbank als persistente Wissensbasis dient, etwa für Materialdaten oder gespeicherte Berechnungen. Diese Struktur erlaubt es Verantwortlichkeiten sauber zu trennen und die Anwendung schrittweise weiterzuentwickeln, von einer zunächst eng gekoppelten Web-Applikation bis hin zu einer API-zentrierten Architektur mit klar entkoppelten Komponenten.
Ein entscheidender Vorteil dieses Ansatzes ist der Zugriff über den Browser. Die Anwendung ist unabhängig vom Betriebssystem und Endgerät, muss nicht lokal installiert werden und kann zentral bereitgestellt und gepflegt werden. Gerade in technischen Umgebungen, in denen Berechnungswerkzeuge häufig als lokale Skripte oder Excel-Dateien existieren, schafft eine solche Architektur einen deutlich niedrigeren Zugang und eine bessere Verfügbarkeit des Wissens.
Diese grundlegende Architekturentscheidung bildet das Fundament für alle weiteren technischen Schritte und bestimmt letztlich auch, welcher Technologie-Stack sinnvoll ist und warum.
Software-Stack - eine bewusste Entscheidung
Für diese Architektur gibt es zahlreiche technologische Umsetzungen, von Java mit Spring Boot über Python mit Flask und Django, bis hin zu Ruby on Rails oder JavaScript mit Express. In meiner bisherigen beruflichen Laufbahn war ich stark in der Java-Welt verankert, insbesondere mit Spring Boot. Parallel habe ich Python über viele Jahre für Datenanalyse, Automatisierung und technische Skripte eingesetzt. Für die heat-conduction-app habe ich mich entschieden, die Architektur zunächst mit Flask umzusetzen. Nicht als Gegenentwurf zu Spring Boot, sondern als leichtgewichtigen Startpunkt mit der Möglichkeit die Architektur inkrementell wachsen zu lassen.
Diese Entscheidung ist eng mit Phase 1 des Entwicklungsmodells verknüpft. Ziel ist eine vollständig funktionsfähige, aber schlanke Web-Applikation, die den fachlichen Kern abbildet, ohne frühzeitig unnötige technische Komplexität einzuführen. Die gleiche Architektur lässt sich konzeptionell ebenso in einem Spring Boot-basierten Stack umsetzen, ein direkter Vergleich ist perspektivisch ausdrücklich mitgedacht.
Flask - das Backend für Phase 1
Flask als Backend-Framework erlaubt einen sehr schlanken Einsteig und stellt zunächst nur das notwendige Grundgerüst bereit. Routing, Request-handling und Template-Integration sind schnell aufgesetzt, sodass der fachliche Kern, Domänenmodell, Berechnungslogik und Orchestrierung, früh läufig wird. Erweiterungen wie Datenbankanbindung, Formularverwaltung oder Authentifizierung lassen sich gezielt über Extensions ergänzen. Mehr zur Flask-spezifischen Features werde ich im kommenden Beitrag zu Applikationsstruktur und Implementierungsebene schreiben.
Gerade für Phase 1 ist dieser Ansatz sinnvoll. Ziel ist keine vollständige ausgestattete Enterprise-Anwendung, sondern eine klare, strukturierte Referenzimplementierung, die den fachlichen Kern sauber abbildet und technisch überschaubar bleibt.
Ciao csv - eine Datenbank als Fundament
Ein wesentlicher Bestandteil moderner Applikationen ist eine saubere Datenhaltung. Auch wenn zu Beginn oft nur wenige Daten anfallen und vieles mit CSV-Dateien oder In-Memory-Strukturen lösbar wäre, stößt man damit schnell an Grenzen. Spätestens wenn die Modelle wachsen oder Daten persistent werden sollen, ist ein stabiles Datenfundament entscheidend.
Daher benutze ich von Beginn an ein relationales Datenmodell über SQLAchlemy. Die fachlichen Objekte werden als Modelle abgebildet, Abfragen und Beziehungen sind klar strukturiert und bleiben vom restlichen Anwendungscode sauber getrennt. Als konkrete Datenbank kommt in Phase 1 SQLite zum Einsatz. Sie ist leichtgewichtig, lokal einsetzbar und ideal für frühe Entwicklungsstufen und Prototypen. Gleichzeitig bleibt die Architektur offen. Der spätere Wechsel auf PostgreSQL oder eine andere produktive Datenbank ist Teil von Phase 2 und mit geringem Anpassungsaufwand möglich.
Damit ist Datenpersistenz von Anfang an architektonisch sauber eingeplant, ohne frühzeitig unnötige Betriebs- und Infrastrukturthemen zu erzwingen.
Server Side Rendering für Phase 1
Neben dem Backend und der Datenbank ist das Frontend der dritte zentrale Baustein der Anwendung. Für Phase 1 setze ich auf Server-Side-Rendering (SSR) mit klassischen HTML-Templates.
Der Fokus liegt hier auf schnell sichtbarer Funktionalität, Eingaben, Berechnungen und Ausgaben sollen ohne zusätzlichen Frontend-Overhead direkt nutzbar sein. SSR ermöglicht genau das und hält die Gesamtarchitektur in der frühen Phase einfach. Die Templates übernehmen die Darstellung, das Backend steuert Logik und Datenfluss. Ergänzend nutze ich Bootstrap, um mit überschaubarem Aufwand funktionale, responsive Oberflächen zu erstellen. Das Ergebnis sind klar strukturierte Seiten, die für technische Anwendungen und interne Tools vollkommen ausreichend sind.
Auch diese Entscheidung ist phasenbezogen. Eine frühzeitige Einführung komplexer Frontend-Architekturen würde unnötige Komplexität erzeugen. Der SSR-Ansatz bildet eine stabile Basis, auf der sich die Anwendung fachlich entwickeln kann und die später problemlos durch eine API- oder SPA-basierte Lösung ergänzt oder ersetzt werden kann.
Damit ist Phase 1 abgeschlossen, eine vollständige, leichtgewichtige Web-Applikation mit Backend, Datenbank und Frontend, die den fachlichen Kern abbildet und Raum für Weiterentwicklung lässt.
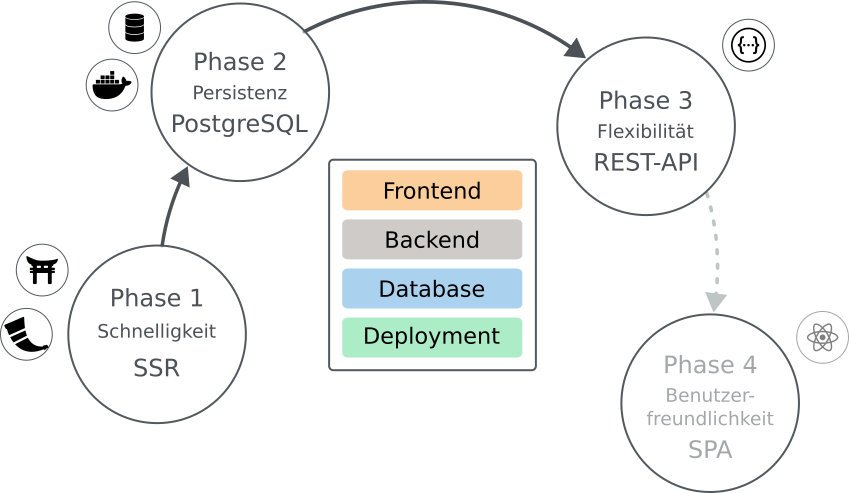
Phase 2 - Persistenz, Benutzer und produktive Datenhaltung
Während Phase 1 den fachlichen Kern und die grundlegende Web-Architektur etabliert, markiert Phase 2 den Übergang von einer rein technischen Referenzimplementierung zu einer produktiv nutzbaren Anwendung. Der Fokus liegt hier auf Persistenz, Benutzerverwaltung und Betriebssicherheit.
Ein zentraler Schritt ist der Wechsel von SQLite auf eine produktive Datenbank wie PostgreSQL. Die Anwendung bleibt dabei architektonisch identisch, lediglich die Infrastruktur und das Datenbank-Backend ändern sich.
Mit der Einführung von Benutzerkonten und Authentifizierung erweitert sich die Anwendung funktional deutlich. Berechnungen können nun benutzerspezifisch gespeichert, wieder geladen und historisiert werden. Ergänzend kommen typische Features hinzu wie Passwort-Reset, E-Mail-basierte Verifikation und grundlegendes Account-Management.
Damit wird aus einen anonymen Berechnungstool eine personalisierte Anwendung, die Wissen, Ergebnisse und Konfigurationen speichert. Phase 2 bildet damit die Brücke zwischen technischer Demo und echter Fachanwendung.
Mehr Flexibilität mit REST-API (Phase 3)
Die bisherige serverseitig gerenderte Frontend-Lösung ist ideal für den schnellen Einsteig und klar strukturierte Anwendungen. Sie erlaubt es, Berechnungen, Datenflüsse und Ergebnisse früh sichtbar zu machen. Mit zunehmendem Funktionsumfang und wachsender Integration in bestehende Systeme stößt dieser Ansatz jedoch an natürliche Grenzen.
An dieser Stelle markiert Phase 3 einen architektonischen Einschnitt, die Einführung einer REST-API. Sie entkoppelt die fachliche Logik von der Darstellungsschicht.Berechnungen, Eingaben und Ergebnisse werden über klar definierte Schnittstellen als JSON-Daten bereitgestellt.
Die Anwendung wird damit von einer primär interaktiven Web-App zu einem Backend-Service, der auch von externen Systemen genutzt werden kann. Eigene Skripte, andere Web-Anwendungen oder Engineering-Tools können direkt auf die Berechnungslogik zugreifen.
Damit wird aus einer isolierten Anwendung eine integrierbare Plattform-Komponente, die sich in bestehende technische Workflows einfügt und Teil einer größeren Systemlandschaft werden kann.
Optional: Single-Page-Application als Phase 4
Mit der Einführung der REST-API ist die fachliche Logik vollständig vom Frontend entkoppelt. Damit ist prinzipiell der Weg frei für eine Single-Page-Application (SPA), etwa auf Basis von React. Dies würde eine möglich Phase 4 darstellen, nicht als zwingender Schritt, sondern als optionale Weiterentwicklung.
Eine SPA ermöglicht interaktive, dynamische Benutzeroberflächen und eine klare Trennung zwischen Backend-Services und Frontend-Anwendung. Gleichzeitig ist der Aufwand nicht zu unterschätzen. Eine bestehende, funktionierende SSR-Oberfläche müsste entweder ersetzt oder parallel weiterentwickelt werden.
Für mich ist dieser Schritt vor allem als Lern- und Vergleichsprojekt interessant. Während der Backend-Fokus klar auf Architektur, Persistenz und Schnittstellen liegt, eröffnet eine SPA neue Perspektiven auf UI-Design, Komponentenmodelle und reaktive Oberflächen.
Wichtig ist, die Architektur der vorherigen Phasen ist so gestaltet, dass dieser Schritt möglich, aber nicht erforderlich ist. Der fachliche Mehrwert entsteht bereits in Phase 2 und 3.
Von Anfang an mitgedacht: Deployment und Betrieb
Wenn Backend, Datenbank und Frontend ineinandergreifen, stellt sich früh die Frage nach dem Betrieb der Anwendung. Für die Demo-App setze ich bereits ab Phase 1 auf Container-Technologien wie Docker und Podman. Sie erlauben es, die Anwendung inklusive aller Abhängigkeiten in einer definierten, reproduzierbaren Umgebung zu betreiben.
In Phase 1 bedeutet das, die Anwendung läuft containierisiert, nutzt SQLite und kann lokal oder auf einem einfachen Server konsistent gestartet werden. Die Containerisierung ist dabei weniger eine Skalierungsmaßnahme, sondern vor allem ein Mittel zur Abgrenzung von Entwicklungs- und Laufzeitumgebung.
Der zentrale Vorteil liegt in der Reproduzierbarkeit und Portabilität. Egal ob Entwicklung, Test oder späterer Betrieb, die Umgebung bleibt konsistent. Versionierte Images, definierte Startparameter und saubere Abhängigkeiten vermeiden typische Probleme klassischer Skript- oder Einzelplatzlösungen.
Themen wie externe Datenbank, Cloud-Deployment, CI/CD-Pipelines oder automatisierte Tests gehören für mich zu späteren Evolutionsstufen. Sie sind nicht Teil der ersten Phase, die Architektur ist jedoch von Anfang an so angelegt, dass diese Schritte ergänzt werden können, ohne das System grundlegend umbauen zu müssen.
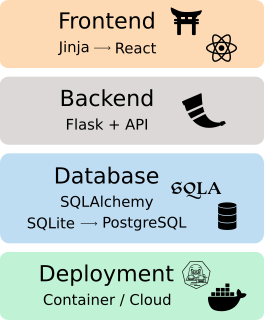
Stack-Fazit
Damit schließt sich der Kreis um meinen gewählten Software-Stack: Flask → SQLAlchemy → SQLite/PostgreSQL → Jinja/REST/optional React → Docker/Podman.
Jede dieser Komponenten ist einer oder mehreren Entwicklungsphasen zugeordnet und erfüllt dort eine klar definierte Rolle. Der Stack erlaubt es, mit einer überschaubaren, leichtgewichtigen Architektur zu starten und diese schrittweise, fachlich wie technisch, weiterzuentwickeln.
Natürlich existieren unzählige Alternativen und Kombinationen, Mit Blick auf die Anforderungen kleiner und mittlerer Berechnungs- und Simulationstools sehe ich hier jedoch eine sehr ausgewogene Lösung, modular, nachvollziehbar und skalierbar, ohne von Beginn an unnötige Komplexität einzuführen.
Gesamt-Fazit
Nach dem persönlichen Einstieg im ersten Teil und dem physikalisch-technischen Kern im zweiten Teil, bildet dieser dritte Teil den Abschluss der Einführungspost-Reihe. Im Mittelpunkt stand die Frage:
Wie lässt sich Ingenieurwissen in eine moderne, nachhaltige Softwarelösung überführen?
Meine Antwort darauf ist kein einzelnes Tool oder Framework, sondern ein Zusammenspiel aus Denkmodellen und Strukturprinzipien, den funktionalen Bausteinen als Übersetzer zwischen Ingenieurproblem und Software, eine passenden Softwarearchitektur, ein bewusst gewählter Technologie-Stack und das klar strukturierte 4-Phasen-Modell, das die Entwicklung von der ersten Berechnung bis zur produktiv nutzbaren Web-Applikation begleitet.
Aus meiner bisherigen Laufbahn, von Matlab und Excel/VBA über Python-Skripte bis hin zu Java-Backends, weiß ich, wie viel Potential in ingenieurgetriebenem Softwaredesign steckt. Leichtgewichtige, modulare Web-Applikationen bieten aus meiner Sicht eine besonders geeignete Form, Berechnungs- und Projektierungswissen strukturiert, transparent und langfristig nutzbar zu machen. Sie fördern den Wissensaustausch, erhöhen die Nachvollziehbarkeit und unterstützen den Übergang zu moderner Softwareentwicklung.
Mit der heat-conduction-app möchte ich zeigen, dass der Weg zur von der technischen Formel zur strukturierten Web-Applikation keine Bruch, sondern ein systematischer, gut planbarer Prozess ist. In vielen Fällen ist er eine nachhaltigere und besser wartbare Alternative zu isolierten Excel-Lösungen oder rein skriptbasierten Tools.
Mit diesem Artikel ist der konzeptionelle Rahmen gesetzt. In den kommenden Beiträgen geht es nun weg von Modellen und Prinzipien hin zur konkreten Umsetzung der heat-conduction-app.
Als Nächstes folgen
- Meilenstein 1: Applikationsstruktur - Vom Konzept zur konkreten Implementierung
- Meilenstein 2: Erste Berechnung läuft - Die Formel als Service-Modul
Ich freue mich, wenn du mich bei dieser Umsetzung begleitest.
Feedback, Fragen oder Anregungen sind jederzeit willkommen, gerne per Email oder auch auf LinkedIn.