Datenbankintegration - die Anwendung bekommt ein Gedächtnis
heat-conduction-app: Referenzprojekt für moderne Backend- und Webarchitektur
Persistenz Datenbankintegration Test-Diven-Development (TDD) SQLite SQLAlchemy Backend heat-conduction-app
← Zurück zur Übersicht | ← Meilenstein 3 - Erste UI-Demo | Meilenstein 5 - Deployment →
Einleitung
Im Meilenstein 3 - erste UI-Demo wurde eine einfache Benutzeroberfläche auf Basis von HTML und Jinja2 im Sinne des Server-Side-Rendering (SSR) umgesetzt. Die Fachlogik der Anwendung lässt sich damit erstmals über eine grafische Oberfläche ansteuern.
Für jede Berechnung müssen jedoch weiterhin alle Eingabeparameter manuell über Formularfelder eingegeben werden. Dazu gehört auch die Wärmeleitfähigkeit λ, ein materialspezifischer Wert.
An diesem Punkt setzt der nächste Entwicklungsschritt an. Anstatt den Wärmeleitwert manuell einzugeben, wird er aus einer Materialdatenbank geladen. Der Benutzer wählt ein Material über ein Dropdown-Feld aus, und der zugehörige λ-Wert wird für die Berechnung verwendet.
Die Anwendung erhält eine Persistenzschicht, eine Datenbank zur Speicherung der Materialdaten und eine Repository-Schicht zur gekapselten Datenbankanbindung.
Projektkontext
Dieser Artikel ist Teil zur Serie zur heat-conduction-app. Der aktuelle Stand ist im Repository verfügbar, die Anwendung läuft produktiv unter einer eigenen Subdomain.
- Phase 1 abgeschlossen
- Deployment (M5)
- Datenbankintegration (dieser Artikel)
- Erste UI-Demo (M3)
- Erste Berechnung läuft (M2)
- Projektgerüst (M1)
Einführung und Hintergrund?
Einleitung
lesen
Ziel des Meilensteins
Ziel dieses Meilensteins ist es, die Materialauswahl in die Benutzeroberfläche zu integrieren und den zugehörigen Wärmeleitwert in die Berechnung zu übernehmen
Dazu lädt die Anwendung die verfügbaren Materialien aus der Datenbank, stellt sie als Auswahl im Formular bereit und übergibt den Wärmeleitwert des gewählten Materials an den Berechnungsservice.
Die Umsetzung erfolgt testgetrieben. Jeder Implementierungsschritt wird zunächst durch entsprechende Tests vorbereitet und anschließend umgesetzt.
Parallel dazu steht die Trennung der Verantwortlichkeiten als Architekturprinzip. Neben der Datenbank selbst wird eine Repository-Schicht eingeführt, die alle Datenbankzugriffe kapselt und als Schnittstelle zwischen Persistenz und Anwendung dient. Der Service bleibt dabei DB-agnostisch, das heißt er kennt keine Datenbank, keine ORM-Modelle und keine Repositories. Die fachliche Berechnungslogik bleibt von der Infrastruktur getrennt.
Umsetzungsschritte
Die Umsetzung lässt sich anhand der Verantwortlichkeiten grob in drei Schritte gliedern. Zunächst steht die Persistenz im Mittelpunkt, die Initialisierung der Datenbank, die Definition eines ersten ORM-Modells und die Einführung einer Repository-Schicht. Darauf aufbauend werden Route und Formular auf eine Berechnung mit Materialauswahl umgestellt. Abschließend wird die Benutzeroberfläche angepasst, sodass das Formular ein Dropdown-Feld zur Materialauswahl bereitstellt.
Persistenz - Datenbank, ORM und Repository
Die Einführung der Persistenz erfolgt in mehreren Schritten, zunächst wird die Datenbank konfiguriert, anschließend ein ORM-Modell definiert und schließlich eine Repository-Schicht eingeführt, die den Zugriff auf die Daten
Initialisierung und Konfiguration der Datenbank
Im Einführungspost - Teil 3 habe ich bereits SQLAlchemy eingeführt. SQLAlchemy ist ein leistungsfähiges Framework für relationale Datenbanken in Python. Es unterstützt verschiedene Datenbanksysteme und bietet sowohl ein High-Level-ORM als auch Low-Level-Zugriff auf datenbankspezifische SQL-Funktionen.
Für die Integration in Flask verwende ich die Erweiterung
Flask-SQLAlchemy, die als Wrapper für
SQLAlchemy dient und die Einbindung in Flask-Anwendungen
vereinfacht. Wie alle Extensions wird Flask-SQLAlchemy zentral
in der Flask-Subklasse CoreApp initialisiert.
Zusätzlich muss die Datenbankverbindung konfiguriert werden.
In der ersten Phase der Anwendung wird eine leichtgewichtige
SQLite Datenbank verwendet. Sie ist Teil der Anwendung und wird
über die .env-datei und die
Config-Klasse konfiguriert.
class Config:
"""Base configuration with default settings."""
...
SQLALCHEMY_DATABASE_URI = os.getenv("DATABASE_URI", "sqlite:///database.db")
SQLALCHEMY_TRACK_MODIFICATIONS = False
Nach der Initialisierung wird die Datenbank im Verzeichnis
/instance/database.db angelegt.
Material ORM Modell
Die Infrastruktur zur Datenbankanbindung ist im Modul
models.py gekapselt. Dieses Modul liegt auf
Anwendungsebene und steht damit allen Komponenten, wie
main, api oder späteren Erweiterungen,
zur Verfügung.
Innerhalb dieses Moduls werden die Tabellen der Datenbank als ORM-Modelle definiert. Für die Materialdaten wird folgende Klasse eingeführt:
class Material(CoreApp.db.Model):
__tablename__ = "materials"
id: so.Mapped[int] = so.mapped_column(primary_key=True)
name: so.Mapped[str] = so.mapped_column(sa.String(64), unique=True)
conductivity: so.Mapped[float] = so.mapped_column(sa.Float)
def __repr__(self) -> str:
return f"Material {self.name}: conductivity {self.conductivity} W/(m*K)"
def to_dict(self) -> dict:
return {"id": self.id, "name": self.name, "conductivity": self.conductivity}
Jedes Material besitzt einen eindeutigen Namen
(unique=True) und einen zugehörigen Wärmeleitwert.
Die Methode ___repr__-Methode ermöglicht eine
kompakte String-Darstellung eines Materials, während
to_dict ein Materialobjekt in eine
Dictionary-Struktur transformiert.
Flask-Migrate einrichten
Nach der Initialisierung der Datenbank und der Implementierung
der Material-Klasse könnte die Datenbank
theoretisch mit
db.create_all()
erstellt werden. Diese Methode hat jedoch einen entscheidenden
Nachteil, Änderungen am Datenbankschema lassen sich damit nicht
ohne weiteres durchführen. Werden Tabellen erweitert oder neue
Tabellen hinzugefügt, müssen alle Tabellen zunächst gelöscht
(db.drop_all()) und anschließend neu erstellt
werden, dies bedeutet den Verlust der gespeicherten Daten.
Für produktionsnahe Anwendungen ist daher ein Migrationssystem notwendig. Hier kommt Alembic zum Einsatz. Alembic erkennt Änderungen am Datenbankschema und ermöglicht deren versionierte Migration, ähnlich wie Versionskontrolle bei Quellcode.
In der Flask-Anwendung wird Alembic über die Erweiterung
Flask-Migrate integriert. Flask-Migrate bindet
Alembic direkt in die flask-CLI ein und wird,
analog zu Flask-SQLAlchemy, zentral in der
CoreApp initialisiert.
Wichtig ist dabei, dass das Modul models.py in der
Application Factory importiert wird, damit Alembic die
definierten Modelle erkennt.
Die initiale Erstellung der Datenbank erfolgt anschließend über die CLI:
flask db init
flask db migrate -m "create materials table"
flask db upgradeDabei wird ein Migration-Repository angelegt, anschließend eine Migration mit der Nachricht "create materials table" erzeugt und schließlich auf die Datenbank angewendet.
Weitere Schemaänderungen werden später über dieselben Befehle durchgeführt:
flask db migrate -m "message"
flask db upgradeRepository einführen
Das Modul app/main/repository.py bildet eine eigene
Schicht, die sämtliche Datenbankzugriffe kapselt. Dadurch
bleiben Route und Service unabhängig von der konkreten
Persistenzimplementierung.
Die Persistenzschicht kann so gezielt getestet werden, während die übrigen Komponenten weiterhin nur über definierte Funktionen mit den Daten arbeiten. Darüber hinaus können diese Funktionen später auch von anderen Teilen der Anwendung, z.B. der API, wiederverwendet werden.
Für den aktuellen Anwendungsfall werden zunächst zwei Funktionen implementiert:
def get_all_materials() -> list[Material]:
...
def get_material_by_id(id: int) -> Material | None:
...
Parallel dazu werden entsprechende Tests
tests/main/test_repository.py definiert:
def test_create_material(session):
...
def test_get_material_by_id(session):
...
def test_get_material_by_invalid_id(session):
...
def test_get_all_materials(session):
...
Für die Tests wird in conftest.py eine Fixture
definiert, die jeder Testfunktion Zugriff auf eine temporäre
Datenbank bereitstellt. Die Datenbank wird dabei für jede
Testfunktion neu initialisiert (scope="function"),
so dass keine unbeabsichtigten Wechselwirkungen zwischen
einzelnen Tests entstehen.
Befüllen der Datenbank - per CLI-Befehl
Nachdem die Datenbank und die erste Tabelle angelegt sind, stellt sich die Frage, wie die initialen Materialdaten in die Tabelle gelangen. Für solche Ausgangsdaten, auch als Seed-Daten bezeichnet, gibt es verschiedene Ansätze. Sie können beispielweise über eine Administrationsoberfläche eingegeben oder aus externen Dateien importiert werden.
Für die heat-conduction-app wird stattdessen ein CLI-Befehl verwendet, der die Datenbank mit einer definierten Liste von Materialien befüllt. Dieses Vorgehen hat mehrere Vorteile, die Initialdaten sind reproduzierbar, versionierbar und lassen sich in automatisierte Test- und CI-Umgebungen integrieren.
Flask stellt dafür eine integrierte CLI bereit. Eigene Befehle
können über AppGroup definiert und anschließend in
der Application Factory registriert werden. Nach der
Registrierung lassen sich die Befehle über das Schema
flask <group-name> <command-name>in der Konsole aufrufen.
Die Implementierung des Befehls
seed-materials sieht wie folgt aus:
data = AppGroup("data", short_help="Data seed commands")
materials = [
{"name": "Steel", "conductivity": 50.0},
{"name": "Aluminium", "conductivity": 205.0},
{"name": "Plastic", "conductivity": 0.2},
]
@data.command("seed-materials")
def seed_materials():
created = 0
updated = 0
_session = CoreApp.db.session
for material_data in materials:
material = Material.query.filter_by(name=material_data["name"]).first()
if material:
material.conductivity = material_data["conductivity"]
updated += 1
else:
_session.add(Material(**material_data))
created += 1
_session.commit()
click.echo(f"Created {created} materials, updated {updated}.")
Der Befehl prüft zunächst, ob ein Material mit dem jeweiligen
Namen bereits existiert. Falls ein Eintrag vorhanden ist, wird
der Wärmeleitwert aktualisiert, andernfalls wird ein neues
Material angelegt. Dadurch lässt sich der Befehl mehrfach
ausführen, ohne die Eindeutigkeit des name-Attribut
zu verletzen.
Eine Testfunktion in tests/test_cli.py stellt
sicher, dass der CLI-Befehl korrekt ausgeführt wird und die
erwarteten Materialeinträge in der Datenbank vorhanden sind.
Anpassung der Route - Berechnung mit Materialauswahl
Nachdem die Datenbank befüllt ist, muss die Benutzeroberfläche und Route so angepasst werden, dass Materialien ausgewählt werden können und der zugehörige Wärmeleitwert in die Berechnung einfließt.
Ein zentraler Bestandteil der Route ist die Formular-Klasse
ConductionForm, über die die Eingabedaten per
POST-Request an die Anwendung übergeben werden. Daher wird
zunächst die Formularklasse überarbeitet. Das bisherige
FLoatField für die Wärmeleitfähigkeit wird durch
ein SelectField zur Materialauswahl ersetzt.
In der View-Funktion conduction im Route-Modul, die
die Orchestrierung zwischen Repository-Schicht, UI-Schicht und
Service-Schicht übernimmt, kommen zwei zusätzliche Aufgaben
hinzu.
-
Das
SelectFieldim Formular wird mit allen verfügbaren Materialien aus der Datenbank befüllt. Dazu werden Materialname und IDs überget_all_materialsaus der Repository-Schicht geladen und als Auswahloptionen im Dropdown bereitgestellt. -
Bei einem validen POST-Request wird das ausgewählte Material
anhand seiner ID mit
get_material_by_id()aus der Datenbank geladen.
Der Wärmeleitwert des geladenen Materials wird anschließend an den Berechnungsservice übergeben. Der Service selbst bleibt unverändert und datenbankunabhängig. Er kennt weder Datenbank, ORM-Modelle noch Repository-Funktionen und arbeitet ausschließlich mit den übergebenen Eingabewerten.
Die Änderungen an Formular und Route erfordern Anpassungen der
Tests in tests/main/test_routes.py, um die korrekte
Interaktion zwischen Route, Repository und Service
sicherzustellen.
Anpassung der UI und ein bisschen JavaScript
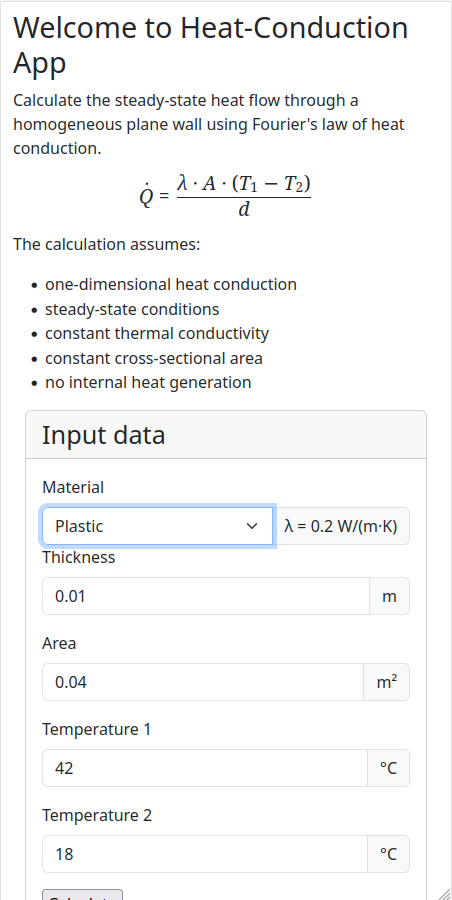
Der letzte Schritt dieses Meilensteins, und für den Anwender
sichtbare Teil, ist die Anpassung der Benutzeroberfläche. Dazu
wird im Template index.html.jinja das bisherige
conductivity-form-control Feld durch ein
form-select-Feld ersetzt, das alle verfügbaren
Materialnamen als Auswahloption enthält.
Um die Benutzerfreundlichkeit zu verbessern, wird zusätzlich der zugehörige Wärmeleitwert dynamisch angezeigt sobald ein Material ausgewählt wird. Dafür wird beim Rendern des Templates eine Liste aller Materialien an das Template übergeben. Ein kleines JavaScript übernimmt die Aktualisierung der Anzeige. Es reagiert auf das Auswahl-Event des Dropdown-Felds und zeigt den zum gewählten Material gehörenden Wärmeleitwert.
An dieser Stelle ist JavaScript sinnvoll, da clientseitige Events wie eine Änderung der Dropdown-Auswahl nicht allein über Server-Side Rendering mit Jinja2 verarbeitet werden können. Alternativ wäre es möglich, die Wärmeleitwerte direkt im Dropdown zu hinterlegen oder eine statische Tabelle mit Materialwerten anzuzeigen. Aus Sicht der Benutzerfreundlichkeit ist die gewählte Variante übersichtlich und intuitiv.
JavaScript wird auch in späteren Projektphasen eine Rolle spielen, sodass diese Erweiterung zugleich einen ersten Einstieg in clientseitige Interaktionen innerhalb der Anwendung darstellt.
Zusammenfassung und Ausblick
Mit diesem Meilenstein erhält die heat-conduction-app eine erste Persistenzschicht in From einer SQLite-Datenbank sowie einer Repository-Schicht, die die Datenbankzugriffe kapselt.
Auch wenn die Materialtabelle zunächst nur einen kleinen Anwendungsfall abdeckt, die komfortable Auswahl eines Materials für die Berechnung, bildet sie eine Grundlage für spätere Erweiterungen. In Phase 2 des Projekts wird die Datenbank eine größere Rolle spielen.
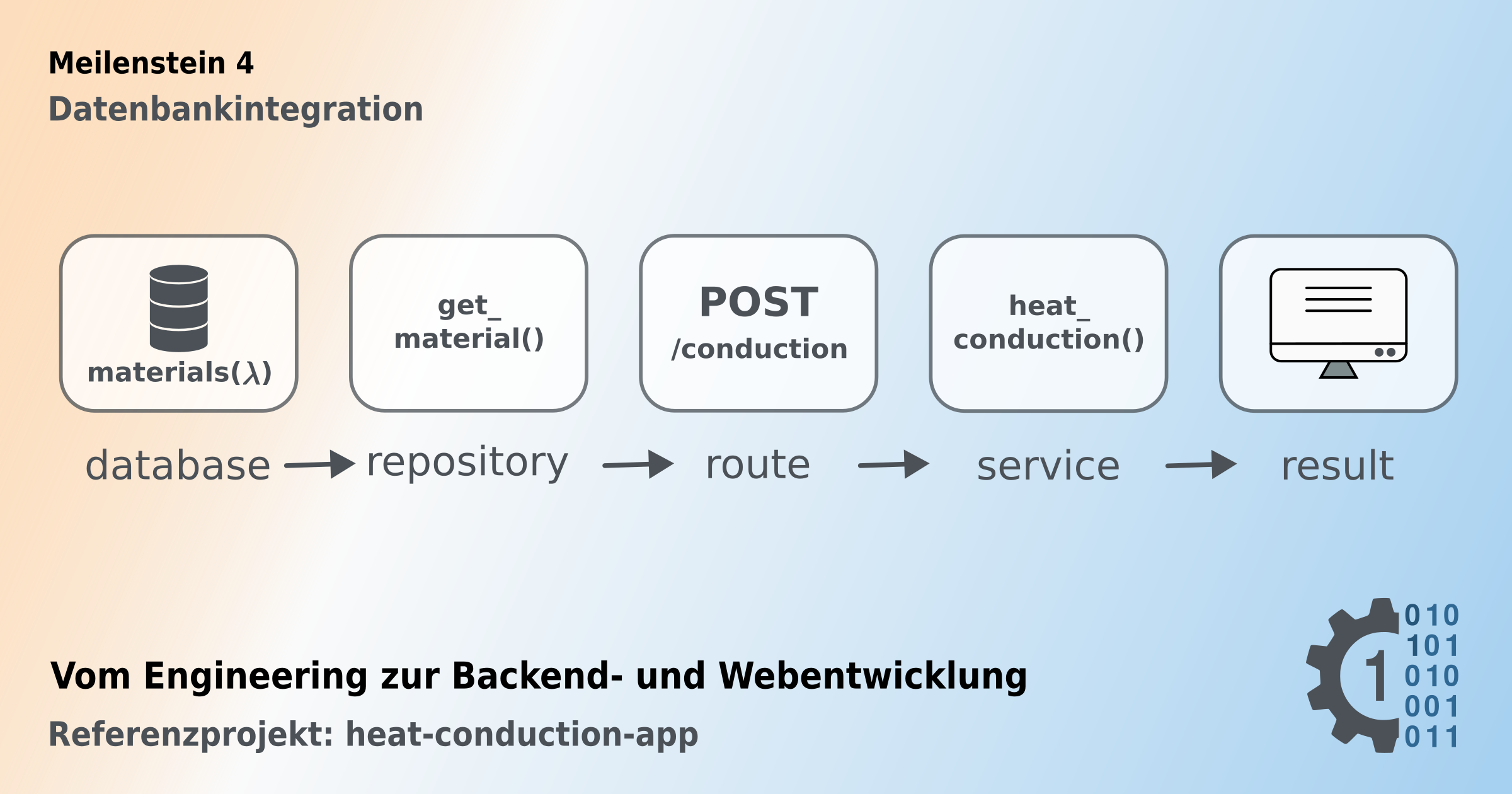
Bei der Umsetzung wurde darauf geachtet, die Verantwortlichkeiten zu trennen. So bleibt die fachliche Berechnungslogik unabhängig von der Persistenzschicht und arbeitet mit den übergebenen Eingabewerten. Der Datenfluss innerhalb der Anwendung lässt sich wie folgt darstellen:
Database
↓
Repository
↓
Route
↓
Service
↓
ResultMit der dynamischen Anzeige des Wärmeleitwerts wurde eine erste clientseitige Interaktion mit JavaScript eingeführt. Während Jinja2 viele dynamische Inhalte serverseitig rendern kann, sind für reaktive Benutzerinteraktionen im Browser häufig clientseitige Lösungen erforderlich.
Mit diesem Meilenstein ist das Projekt einen weiteren Schritt in Richtung eines funktionsfähigen Prototyps gegangen. Im nächsten Meilenstein folgt das containerisierte Deployment, das zugleich den Abschluss der Phase 1 - lauffähiger Prototyp des Projekts bildet.
Feedback, Fragen oder Anregungen sind jederzeit willkommen, gerne per Email oder auch auf LinkedIn.