Warum ich ein eigenes Tool nur zum Aufsetzen von Python-Projekten gebaut habe
init-pyproj App - ein kleines Bash-Tool, das mir täglich Zeit spart und Struktur in meine Projekte bringt
CLI Python Projekt-Setup Automatisierung Linux
Motivation
Das wiederkehrende Setup-Problem
Wer regelmäßig neue Python-Projekte startet, kennt den Aufwand
zu Beginn: Verzeichnisse anlegen, virtuelle Umgebung einrichten,
Abhängigkeiten installieren, Git initialisieren,
.env und README anlegen. Bevor man
überhaupt eine Zeile Code schreibt, vergeht schnell eine Stunde.
Warum Automatisierung sinnvoll ist
Viele dieser Schritte sind in nahezu jedem Projekt gleich, unabhängig davon ob man ein Tool zur Datenauswertung, Web-Scrapping oder auch eine vollständige Web-App mit Datenbank Anbindung erstellt. Ein standardisierter, automatisierter Ablauf spart nicht nur Zeit, sondern sorgt auch für einheitliche Strukturen, reproduzierbare Setups und weniger Fehlerquellen, besonders bei mehreren Projekten oder Teamarbeit. Also einige Gründe das Ganze bis zu einem sinnvollen Level zu automatisieren.
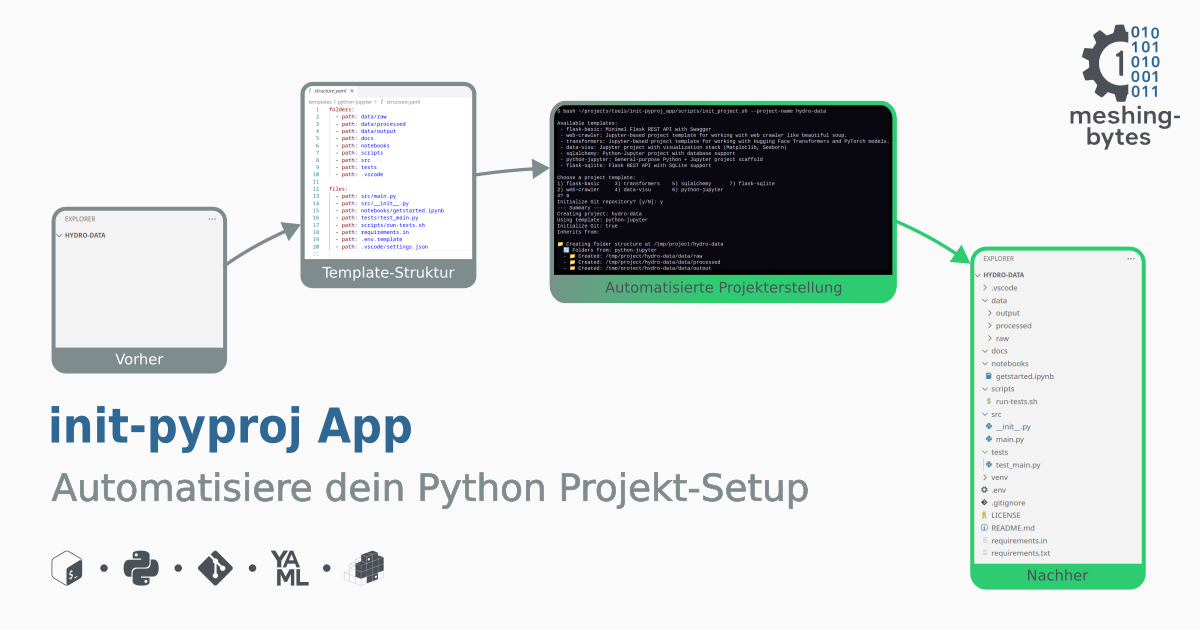
Vom manuellen Setup zum automatisierten Projektstart
Ziel war es, ein Tool zu entwickeln, das den kompletten Projekt-Startprozess automatisiert, vom Anlegen der Ordner bis zum Initialen Git-Commit. Und dabei flexibel genug bleibt, um unterschiedliche Projekttypen (Web-Applikation, Datenauswertung, Web-Scrapping) abzudecken.
Warum Bash?
Da die meisten Befehle zum Einrichten eines Projekts in der Bash durchgeführt werden, lag es nahe ein solches Tool als Bash-Skript zu erstellen. Damit kann es später auch auf Projekte in anderen Programmiersprachen erweitert werden, zum Beispiel für statische HTML-Projekte oder auch React. Nachteil, das Ganze ist zunächst nur unter Linux einsetzbar, aber prinzipiell kann es natürlich auch an die Windows PowerShell angepasst werden.
Was soll alles automatisiert werden?
Zunächst stellt sich die Frage was soll alles automatisiert werden, 5 Punkte sind aus meiner Sicht grundlegend:
- Projektstruktur: automatisch angelegte, einheitliche Ordner (src, test, doc, data).
- Virtuelle Umgebung: saubere Isolation pro Projekt.
-
Dependency Management:
requirements.in+pip-toolsfür reproduzierbare Umgebungen. -
Basisdaten:
.env,README.md,LICENSE. -
Versionsverwaltung: Git-Repo inkl.
.gitignoreund initialem Commit.
Diese Basis definiert den Kern der Automatisierung, alles darüber hinaus (Starter-Dateien, Tests, API etc.) bildet den modularen, template-spezifischen Teil.
Auf dieser Grundlage entstand das eigentliche Tool, ein modulares Bash-System, das Schritt für Schritt die gesamte Projekterstellung abbildet.
Umsetzung
Das Tool basiert in erster Line auf
Bash-Skripten Ausgehend vom Hauptskript
init_project.sh werden
Unterskripte aufgerufen, die jeweils eine klar
definierte Aufgabe übernehmen, z.B. das Erstellen von Ordnern,
das Einrichten der virtuellen Umgebung oder das Kopieren der
Starter-Dateien. Diese modulare Struktur macht das System leicht
erweiterbar: einzelne Funktionen können einfach aktiviert,
deaktiviert oder durch andere Varianten ersetzt werden. Und die
Skripte bleiben zudem übersichtlich.
Da während der Ausführung eine Vielzahl von Schritten erfolgt, kann das Erstellen eines Projektes auch mal eine kurze Zeit in Anspruch nehmen. Damit der Anwender den Fortschritt gut nachvollziehen kann, wird nahezu jeder Schritt in der Konsole ausgegeben und zusätzlich mit einem schicken Markdown-Emoji aufgehübscht.
Templates: Informationen und Starter-Dateien
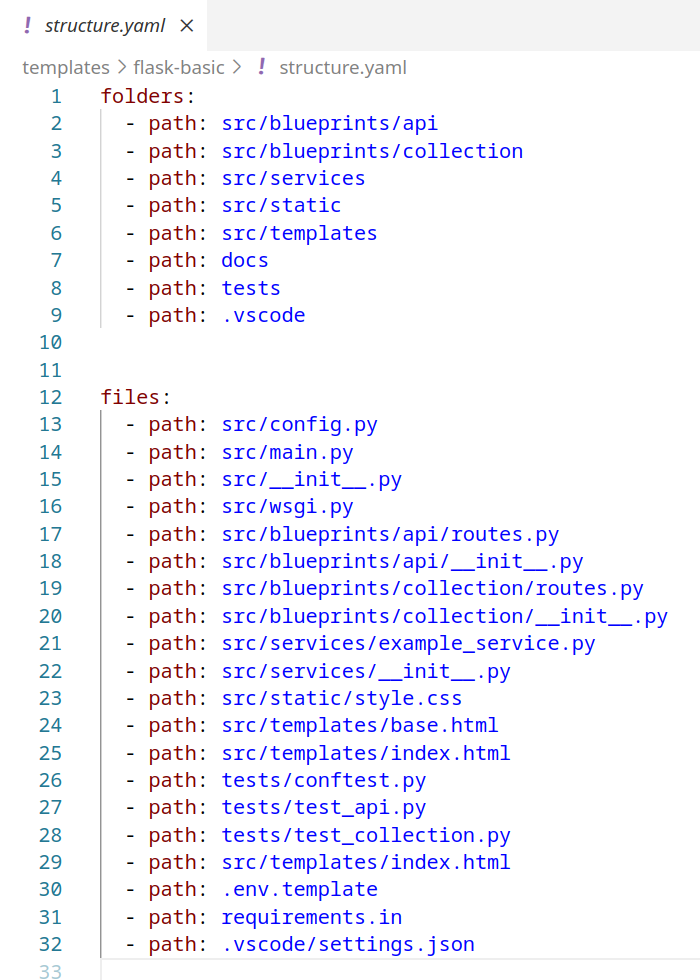
structure.yaml, sie definiert den
kompletten Projektbaum, die zu erstellenden Verzeichnisse
sowie die Art, wie die Starter-Dateien behandelt werden.
Jedes Template verfügt über eigene Konfigurationsdateien, die definieren, welche Verzeichnisse und Daten erzeugt werden und wie Starter-Dateien behandelt werden (kopiert, gemerged oder injected). Diese Informationen liegen in zwei YAML-Dateien:
-
template.meta.yamlenthält Meta-Informationen die beim Durchführen des Scripts in der Bash hilfreiche Informationen bereitstellen (Beschreibung, Abhängigkeiten, Basis-Template) -
structure.yamlbeschreibt den kompletten Verzeichnisbaum und alle Dateien, die im Projekt angelegt werden sollen.
Zum Einlesen und Verarbeiten dieser Dateien kommt das Tool
yq zum Einsatz, ein leichtgewichtiges Tool zum
Verarbeiten von YAML, JSON, INI und XML Dateien.
Diese Dateien bilden die Grundlage für die Unterskripte
create_file.sh und create_folder.sh.
Damit das funktioniert, müssen im Template Ordner entsprechende
Starter-Dateien vorhanden sein, inklusive einer
requirements.in und .env.template. So
stellt jedes Template sicher, dass
nur die tatsächlich benötigten Abhängigkeiten
installiert werden.
Durchführung
Das Tool wird über das Skript
init_project.sh gestartet. Es lässt sich sowohl
flag-basiert (alle Parameter direkt angeben)
als auch interaktiv (Schritt-für-Schritt
Abfrage in der Bash) verwenden. So ist es für Einsteiger genauso
geeignet, wie für Nutzer, die regelmäßig Projekte aufsetzen und
die Schritt-für-Schritt-Abfrage überspringen möchten.
Hilfe und Übersicht
Um einen Überblick über die korrekte Skript Ausführung zu
bekommen verfügt das Skript über eine Hilfe, die mit dem
Parameter --help angezeigt wird.
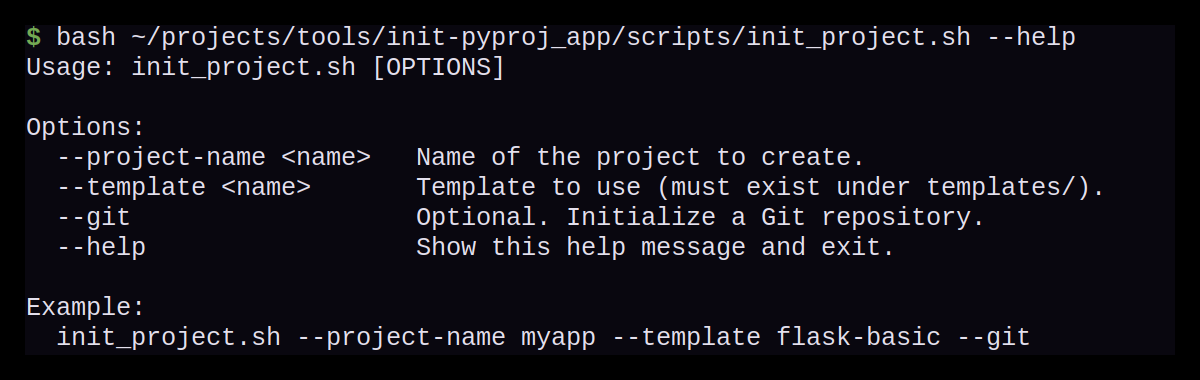
--help zeigt alle verfügbaren Parameter und
Optionen für den Projektstart an.
Flag-basierter Start
Kennt der Anwender bereits alle Parameter kann das Projekt direkt mit einem einzigen Befehl starten:
$ bash init_project.sh --project-name calculator --template
flask-basic --git
Interaktiver Modus
Alternativ kann der Anwender das Tool auch interaktiv nutzen. Dazu muss der Anwender zunächst nur den Projektnamen festlegen, alle weiteren Informationen fragt das Skript nacheinander ab.
$ bash init_project.sh --project-name calculator
Im nächsten Schritt werden alle verfügbaren Templates aufgelistet mit einer kurzen Beschreibung und der Anwender kann das Template seiner Wahl eingeben.
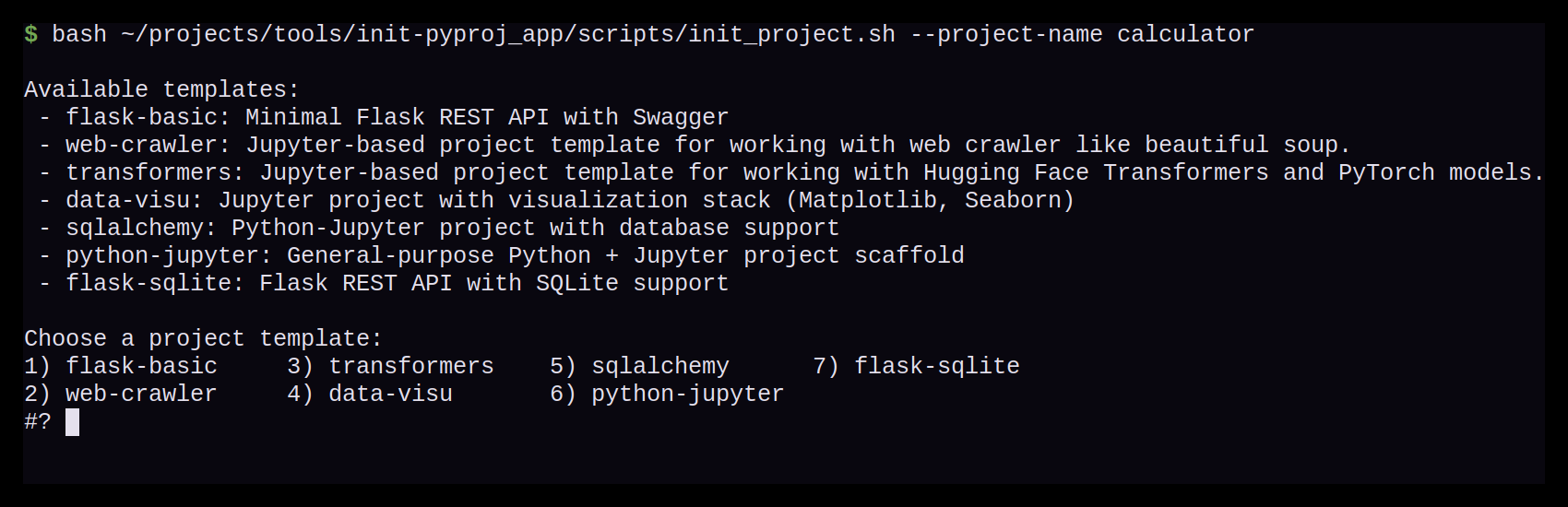
Nach der Auswahl wird der Anwender gefragt, ob ein Git Repository automatisch angelegt werden soll. Anschließend erhält der Anwender eine kurze Zusammenfassung der gewählten Optionen, bevor die Projekterstellung startet.
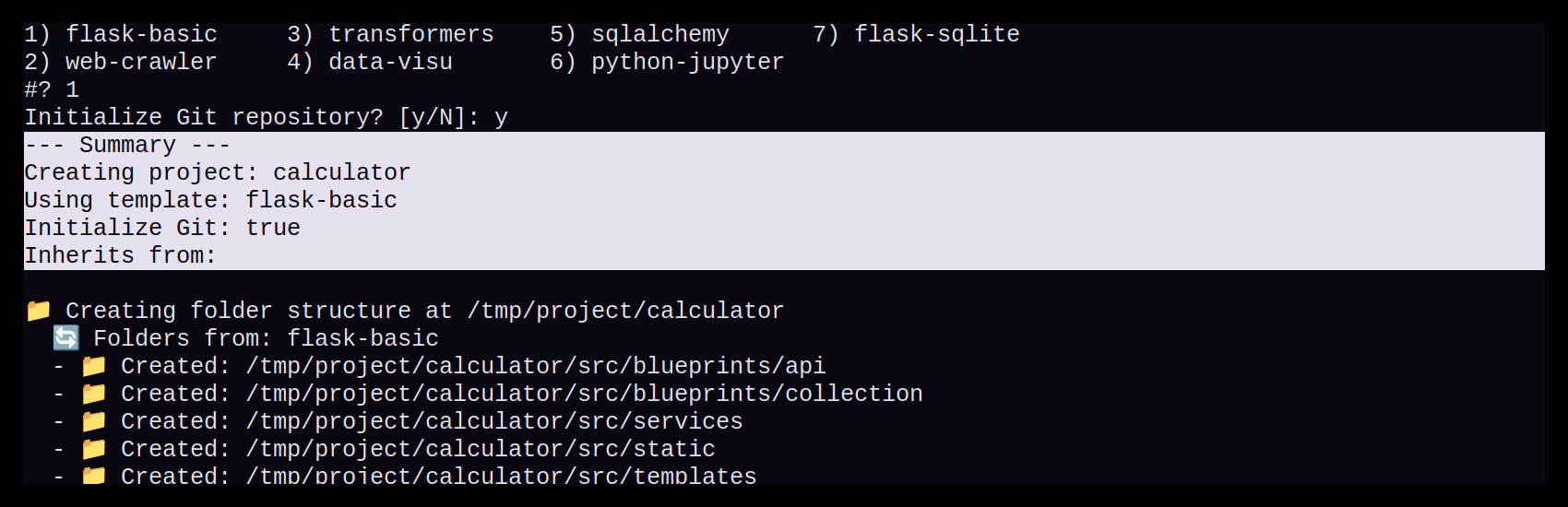
Automatisierte Projekterstellung
Nun werden Schritt für Schritt alle Projekt-Komponenten erstellt:
- Anlegen der Verzeichnisse
- Kopieren der Starter-Datiene
- Erstellen und Aktivieren der virtuellen Umgebung
- Installation der Abhängigkeiten
- (Optional) Initialisierung des Git-Repositories
Bei erfolgreicher Durchführung erscheint am Ende eine "successfully created" Bestätigung.

Ergebnis
Wenn das Script erfolgreich ausgeführt wurde, entsteht nicht nur ein Projektordner, sondern ein vollständiges Projektgrundgerüst, mit klarer Struktur, installierten Abhängigkeiten und allen wichtigen Starter-Dateien. Damit steht eine solide Basis, auf der direkt mit der eigentlichen Entwicklung begonnen werden kann.
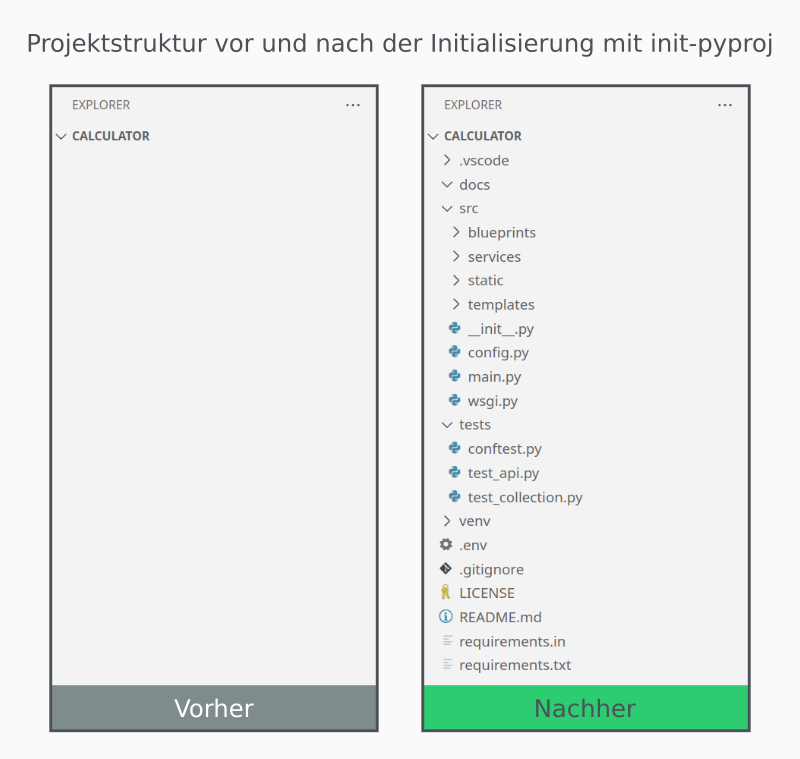
init-pyproj.
Nach der erfolgreichen Erstellung kann jeder selbst entscheiden, wo er im Projekt einsteigt:
-
die
README.mdvervollständigen und das Projekt auf einen Remote-Server pushen, - Testklassen für -Test-Driven-Development_ beginnen,
- einen Services über eine REST-API bereitstellen,
-
oder erste Analysen mit dem bereitgestellten Notebook
(
/notebooks/get_started.ipynb) beginnen.
Dank der verschiedenen Templates ist für viele Anwendungsszenarien, von Web-Apps bis Datenanalyse, ein passendes Grundgerüst vorhanden.
Ein paar Worte zu den Templates
Templates sind das Herzstück von init_pyproj. Sie definieren, wie ein Projekt aufgebaut ist, welche Starter-Dateien erzeugt werden und welche Abhängigkeiten installiert werden. Damit lassen sich unterschiedliche Projektarten, von kleinen Tools bis hin zu komplexen Web-Apps, konsistent und wiederholbar erstellen.
Idee der Templates
Aktuell sind sieben Templates hinterlegt, die
meine häufigsten Projekttypen abdecken. Einige davon sind noch
in einem sehr Stadium (z.B. das
transformers-Template), andere sind bereits
ausgereift.
Wichtig war mir das richtige Verhältnis zwischen Flexibilität und Wartbarkeit zu schaffen:
- Jedes Template enthält nur die für seinen Zweck notwendigen Dateien und Abhängigkeiten.
- Überschneidungen zwischen Templates werden durch Vererbung aufgelöst (siehe unten).
- Übersichtliche und leicht anpassbare Struktur, ohne redundante Starter-Dateien zu pflegen.
Beispiel:
Neben dem flask-basic Template gibt es ein
flask-sqlite Template. Beide sind sehr ähnlich,
unterscheiden sich aber in einem wichtigen Punkt:
flask-sqlite bringt direkt Datenbankunterstützung
mit, während flask-basic bewusst minimal bleibt.
Vererbung - weniger Redundanz, mehr Konsistenz
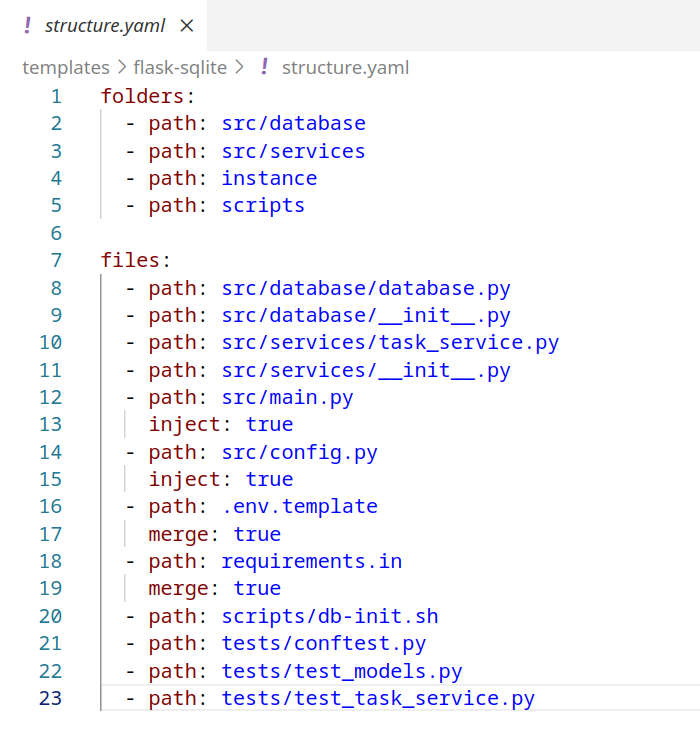
structure.yaml mit
Template-Vererbung. Das Kind-Template erweitert das
Eltern-Template nur um die spezifischen Anpassungen.
Um Redundanzen zu vermeiden, können Templates
von anderen Templates erben. Ein Kind-template
übernimmt dabei automatisch die komplette Struktur und alle
Starter-Dateien seines Eltern-Templates. Nur spezifische
Ergänzungen oder Abweichungen werden in der Kind-Definition
hinzugefügt. Das geschieht über die
structure.yaml des Templates, die mit drei Methoden
arbeitet:
- Path: kopiert eine Datei unverändert.
- Path + merge: hängt den Inhalt der Kind-Datei an die namensgleiche Eltern-Datei an.
- Path + inject: fügt Textblöcke gezielt zwischen Markern in Eltern-Datei ein.
Dieses Feature sorgt dafür, dass Templates leicht erweiterbar bleiben, ohne ständig redundante Daten zu duplizieren und mehrfach zu pflegen. Und gleichzeitig können komplexe Templates auf einer Basis-Struktur aufbauen.
Zusammenfassung in der CLI
Ob ein Template auf einem anderen basiert wird in der Zusammenfassung vor der Projekterstellung unter "Inherits from:" angezeigt:
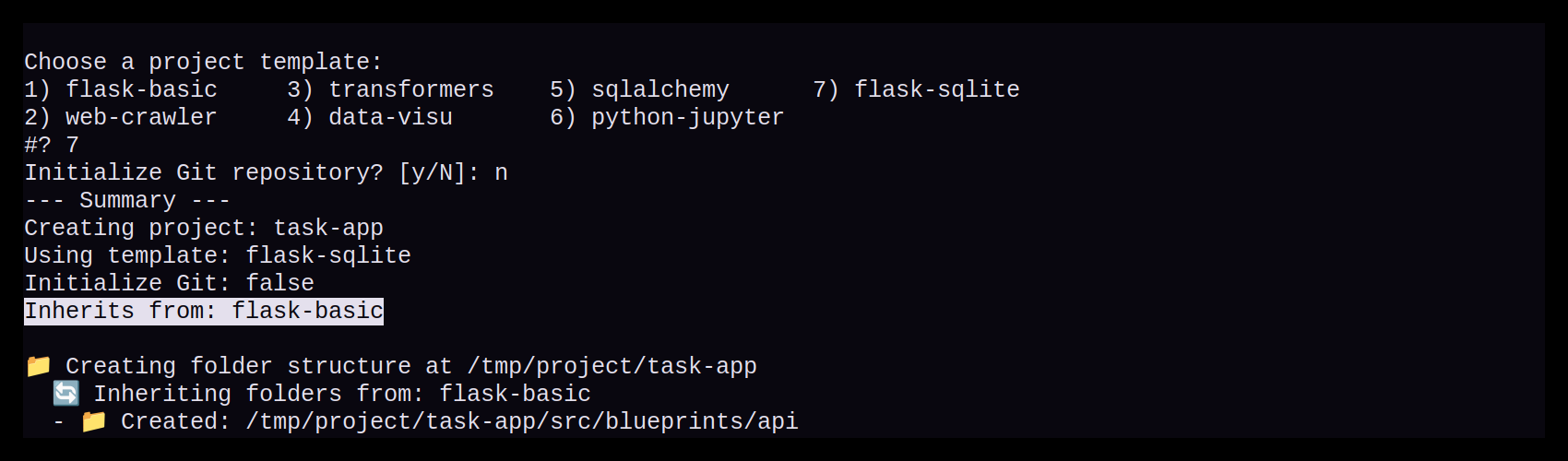
Fazit
Das Template-System ist bewusst modular und erweiterbar angelegt. Damit lassen sich für unterschiedliche Projektanforderungen angepasste Grundgerüste bereitstellen, und gleichzeitig den Pflegeaufwand erträglich halten.
Mit wachsender Projekterfahrung kannst du auch deinen eigenen Templates anlegen oder bestehende erweitern und anpassen. Und hast dann deine persönliche, standardisierte Projektbasis in der du dich schnell zurecht findest.
Abschluss - persönliche Motivation
Die Motivation für das Tool entstand aus einem einfachen Schmerzpunkt: Ich hatte schlicht keine Lust mehr, bei jedem neuen Python-Projekt die immer gleichen Einrichtungsschritte manuell durchzuführen.
Natürlich kostet es zunächst Zeit, ein solches Tool zu entwickeln und zu pflegen. Aber der Aufwand hat sich mehrfach gelohnt, nicht nur, weil es meinen Programmieralltag effizienter macht, sondern auch, weil ich dadurch intensiv mit der Frage beschäftigt habe: Wie möchte ich meine Projekte eigentlich strukturieren und organisieren?
Diese Auseinandersetzung war für mich ein großer Mehrwert des Projekts. Und es macht mir persönlich auch Spaß, solche wiederkehrenden, eher monotonen Aufgaben zu automatisieren und daraus etwas Eigenes entstehen zu lassen.
Wer Lust bekommen hat das Tool auszuprobieren, findet das Repository auf Codeberg: init_pyproj-app. Dort findest du auch die aktuelle Projekt-Readme mit einer Übersicht und weiterführenden Informationen zu den Templates.
Wenn du Anregungen, Ideen oder Feedback hast, freue ich mich über Austausch: .
Der Blog steht noch ganz am Anfang und soll in den kommenden Wochen und Monaten weiter wachsen, Ideen habe ich schon einige. Also schau regelmäßig auf meinem Blog vorbei oder folge mir auf LinkedIn.